Open Pipe Kit
What is a Pipe?
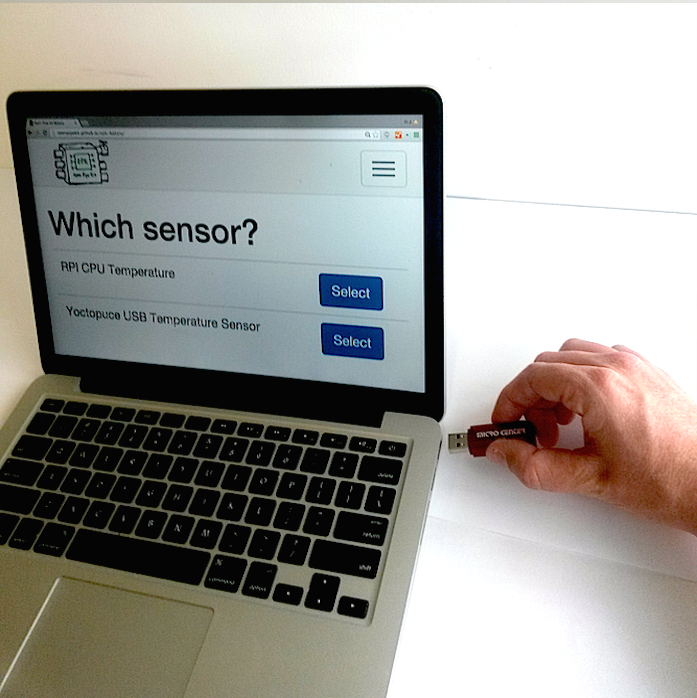
A Pipe is a small device that connects to a sensor and sends data to a location of a user's choosing. Pipes can be built by nontechnical people from readily accessible parts such as the $35 Raspberry Pi computer and a $15 WiFi USB dongle. A Pipe is configured using an easy to use Graphical User Interface that is accessed over WiFi using a smartphone, laptop, or desktop computer.
The OPK Mission
- Empower people without programming knowledge to collect data from a large selection of sensors.
- Fight vendor lock-in, give users the freedom to choose where their data flows to.
- Spur innovation by licensing OPK with an Open Source license so users have the freedom to write new drivers for new sensors coming to market and new types of databases that do not yet exist.
Why Open Pipe Kit?
The internet has often been compared to a system of pipes. Imagine that these pipes carry water: for someone interested in collecting water from a local river in order to store it for later use, then, to date, nearly all the "internet of things" sensor data solutions are like companies that sell customers proprietary pipes and fittings designed to transport the user's water (sensor data) to a remote, hidden reservoir (a cloud-based server); and typically the user is then required to pay a fee in order to access this now-remote resource.
We believe it is vital for people in the fields of sensor journalism, environmental monitoring, and agriculture to have full control over the data they collect, and to be able to use reliable, easily-acquired, open source hardware and software that can be modified and repurposed without permission.
The Open Pipe Kit (OPK) is a system designed to meet this need, based on a Raspberry Pi and Node.js. Users of OPK will be able to collect data from sensors and store it either locally (on microSD) or remotely (on a server of their own choosing, either local or remote).
Who is the audience/user of this project? How will they be impacted?
We are designing this project to be useful for the following groups: Journalists using sensors in their work. Increasingly, professional and citizen journalists are considering the use of low-cost sensor technology in order to investigate environmental concerns. Useful material in support of the urgent need for open infrastructure for sensor journalism projects can be found here: http://science.creativecommons.org/hardware/workshop/ and here: http://towcenter.org/sensors-and-journalism-sensor-journalism-through-open-and-closed-source-initiatives/
Civic Hackers. Many projects now seek to collect sensor data in order to monitor, critique, and improve local infrastructure, especially in urban areas.
Environmental research. Sensors are now being used by many people in the fields of environmental justice and academic research. The Public Lab community is planning to deploy water and air monitors widely in areas where more data collection is urgently needed.
Agriculture and land management. Small- and medium-scale agriculture is now beginning to see the deployment of sensors intended to improve crop yield and optimize soil treament. In all of the above cases, there is a strong and growing need for a secure, simple, open, accessible, and reliable data collection infrastructure. This is what we intend the OPK to provide to these groups.
Development strategy for Open Pipe Kit
We will take a "Ground Computing" approach. This means that the User Interface and data storage can be hosted on the ground in "Ground Servers" where the data is being collected as opposed to on "The Cloud" where other devices store and display data without any other option. We will build on our past efforts to make a stable Ground Server in the Fido project; the Hive project which has given us an API for describing devices, the sensors attached, and storing the data associated; as well as outside efforts from the Dat project for portable and syncable databases of realtime data.
To accomplish our mission we will be utilizing pieces from the Fido project, the Hive project, and the outside Dat project.
- Hive gives us a RESTful API for describing a device, the sensors attached, and storing the data.
- From the Fido project we now have a tested and battle hardened disk image for Raspberry Pi to host Ground Servers in remote locations.
- From both Hive and Fido, we have an over the air software update mechanism that gives user the choice of receiving software updates from our GitHub repo.
- From Fido we have written drivers for many different types of sensors including DustTrak II, Temper1 USB Temperature sensor, Temperature/Humidity Pro for Grove. These will need to be updated according to framework changes.
- From Fido we have software to configure via UI the network settings including WiFi
- Dat makes sensor databases portable for users on the command line, we're going to build a framework and UI for getting sensor data into dat and replicating dat databases to other dat databases that are either local or on the Internet.