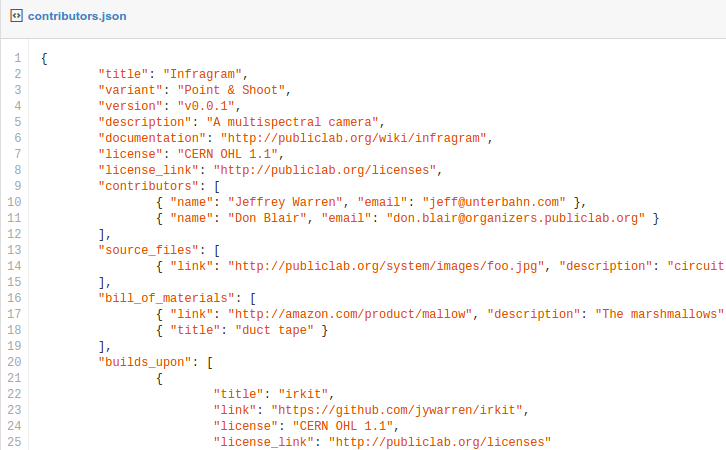
Alicia Gibb of OSHWA and I (I'm on their board) cooked up the idea, chatting a few months ago, of a "spec" for a file similar to the CONTRIBUTORS or CREDITS text files found in some FOSS projects -- a kind of text file format for describing your project and providing key information. So, a little broader than just listing contributors, but really fulfilling all of the Open Source Hardware Definition. As it'd be machine readable, it could form the basis for a repository -- the URLs to these files in different peoples' online posted docs could be scraped and indexed.
This sample has a lot of ideas, some better than others, but the most minimal example would be really short; just title, version, description, license, contributors, and source_files.
Link to Gist example: https://gist.github.com/jywarren/a4dafb0f02e731eacb14
What do you think? It's a slightly more concrete way to kick off any discussions of repositories, and people could begin creating these "contributors.json" files now, which could help in later attempts to create a more comprehensive directory of open hardware projects.
Basically this is just a rough proposal, but it wouldn't be too hard for Public Lab tool pages to provide such a standardized JSON file, and perhaps others would adopt it as a draft standard?
11 Comments
I like that its JSON and that there isn't a hard coded standard. It seems more like a guideline or a best practice, but of course deviation is acceptable.
As an example, a contributor might want to list name, but not email. The JSON structure concedes that possibility without requiring it the way XML might, given a proper DTD.
I'm not sure I understand the
builds_uponfield. If open hardware ends up being like open software, this one field would be some pale comparison of Github's network graph seen on many popular repositories. I just grabbed one of Github's most popular repos this month and here's an example graph: https://github.com/Flipboard/react-canvas/networkA forking, branching, merging network of contributions is best tracked directly by git, mercurial, or something along those lines. Trying to embed that in a human-readable format is going to lead a hairy mess if open hardware becomes anything like open software.
Reply to this comment...
Log in to comment
I was a bit inspired by bower's
bower.jsonor npm'spackage.jsonformats -- and actually, one thought was that the builds_upon would link to more contributors.json files. And that it helps to show upstream licensing. So maybe more following the "includes" paradigm than mirroring how upstream contributions to the same software project are shown.Reply to this comment...
Log in to comment
I think linking to other files would be alright. In that sense, you are emulating a graph by issuing pointers as opposed to trying to copy-by-value important details like license into your copy of
contributors.json. In the git comparison, you're enumerating previous commits or branches but not their contents.There are some issues here, though. Here are two I came up with by thinking about what git does and how this fails to replicate it.
Cloning a repository maintains a snapshot of the entire history up to that point, but not necessarily after it. If
contributors.jsonis changed upstream, that link doesn't mean the same thing it did when it was created.Cloning a repository maintains a copy of all commits up to that point, including all user contributions. If the pointer to some upstream
contributor.jsonbecomes a broken URL, you lose that all historical context and previous contributors from that section of the tree.Reply to this comment...
Log in to comment
ah, to look to bower and npm again on that point of the linked-to-projects changing, we could link to a specific version of the
contributors.jsonfile as they do -- like"link": "https://github.com/jywarren/irkit/contributors.json#0.1.2"or:"link": "https://github.com/jywarren/irkit", "version": "v0.1.2",Reply to this comment...
Log in to comment
That covers the first problem but not the second.
So I think you'd need to do one of two things to really preserve the historical contributors:
Maintain a complete history of the repository by way of version control and build it into the standards and practices. This more or less guarantees all contributors are tracked, and it does not attempt to turn this tracking into something user friendly which is doomed to fail.
Maintain a complete and full copy of every
contributors.json, frozen at the time of forking, inside the currentcontributors.json. This will become very large and ugly, but it's moderately manageable with technology. If one person merged two projects with a common ancestor, then there'd be a lot of redundant information in the full copies ofcontributors.jsonof each project found inside that one person'scontributors.json.Reply to this comment...
Log in to comment
Timestamping would probably be better than versioning because version numbers don't always get used in proper ways. Think of forking a feature branch that is not yet complete and turning it into a new master in a different repository: version didn't get changed yet because the feature branch wasn't yet merged to master. A timestamp should be solid because all changes tend to be timestamped. git would handle this by tracking the entire commit tree for you by tag or commit hash.
Versions could certainly be added along with timestamps. That would help distinguish different forks from the same project being worked on in parallel, the equivalent to git branches.
Reply to this comment...
Log in to comment
Oh here's a crazy idea. You could point at other
contributor.jsonfiles by reference using a universal identifier, aka UUID. https://en.wikipedia.org/wiki/Universally_unique_identifierThe process of generating a UUID for
contributor.jsonfor a given project might be something like this:A new project would have a UUID of all 0s in the contributor file as an initial seed, but step 6 would replace the 0s.
Now your contributor.json file can maintain a series of UUID pointers to the UUID found in each of the upstream's current contributor.json.
In this way, each change could be tracked by a UUID without copying the repository and is highly likely to be a unique fingerprint for that repository at that time. This is a bit of a one-way mapping, unfortunately. Backing out of it would be difficult. It might require caching this information in a repository or something so that a UUID can be mapped to its originating source.
Reply to this comment...
Log in to comment
@warren
What you are talking about reminds me of what Mozilla Science were talking about at the Open Knowledge meetup which Public Labs was also invited to.
I think they are on the same page as you when it comes to standardisation.
@btbonval
My partner uses https://bitbucket.org/.
Reply to this comment...
Log in to comment
@amysoyka bitbucket can use git or mercurial, which are both options I noted in a previous comment. GitHub is not the same as git. I actually have one or two projects, using git, that are on both GitHub and BitBucket at the same time :)
Reply to this comment...
Log in to comment
I had some ideas (talking with @rjstatic) about how a more Bower- or NPM-style utility could parse such files... these are just roughly sketched out ideas -- say we called it "newt":
newt init-- questoinnairenewt register-- tests for presence of req'd docs, clones repos or zipsnewt compile bom-- aggregate/merge BOMs of nested projectsnewt compile bom <string>-- aggregate/merge BOMs with links matching providedstringlike "digikey.com"newt compile price <int>-- calculate unit price forintunitsnewt compile contributors-- compile contributors of nested projectsReply to this comment...
Log in to comment
While not MVP,
newt compile price <int>will be so cool in the future when there is adoption of this sort of thing.Reply to this comment...
Log in to comment
Login to comment.